metagenomics 메타지노믹스
Metagenomics 는 환경 시료 에서 직접 회수 된 유전 물질에 대한 연구입니다 . 넓은 분야는 환경 유전체학 , 생태 유전체학 또는 공동체 유전체학 이라고도합니다 . 전통적인 미생물학 및 미생물 게놈 시퀀싱 및 유전체학 은 배양 된 클론 (clonal) 배양에 의존하지만 , 초기 환경 유전자 시퀀싱 은 천연 샘플에서 다양성 프로파일을 산출하기 위해 특정 유전자 (종종 16S rRNA 유전자)를 복제했습니다 . 이러한 연구 결과는 대다수의 미생물 생물 다양성 재배에 근거한 방법으로 놓친 것이다. [1] 최근 연구 에서는 표본 집단의 모든 구성원으로부터 모든 유전자의 편향된 시료를 얻기 위해 "샷건"또는 PCR지시 시퀀싱을 사용합니다 . [2] 이전에 숨겨진 현미경 적 생명의 다양성을 보여줄 수있는 능력 때문에 메타겐 오믹은 미생물 세계를 볼 수있는 강력한 렌즈를 제공하여 살아있는 세계 전체에 대한 혁명적 인 잠재력을 가지고 있습니다. [3] DNA 시퀀싱의 가격이 계속 강하로서, 메타 지노믹스있게 해주기 미생물 생태 이전보다 훨씬 더 큰 스케일에서 상세히 연구된다.
어원학 [ 편집 ]
용어 "메타 지노믹스는"처음에 의해 사용되었다 조 핸더 즈먼 , 존 클라 디 , 로버트 M. 굿맨 , 숀 F. 브래디, 등, 먼저 1998 년에 출판 등장 [4] 용어 metagenome 아이디어를 참조하는 유전자의 집합 환경으로부터 서열화 된 단일 게놈 은 단일 게놈 의 연구와 유사한 방식으로 분석 될 수있다 . 최근 케빈 첸 (Kevin Chen)과 리어 패쳐 ( Lior Pachter) ( 캘리포니아 대학, 버클리 대학의 연구원 )는 메타 게 노믹스를 "개별 종의 분리 및 실험실 배양이 필요없는 현대의 게놈 기술의 적용"으로 정의했다. [5]
역사 [ 편집 ]
기존의 염기 서열 분석 은 DNA 원천과 동일한 세포 배양으로 시작됩니다 . 그러나 초기 metagenomic 연구는 교양 될 수없고 따라서 sequencing 될 수없는 많은 환경에서 아마 많은 집단의 미생물이 있음을 밝혀냈다 . 이 초기 연구 는 상대적으로 짧고 종내에서 종종 보존 되며 일반적으로 종간에 다른 16S 리보솜 RNA 서열 에 초점을 맞추었다 . 공지 된 배양 된 종에 속하지 않는 많은 16S rRNA 서열이 발견되었다, 비 격리 된 유기체가 많이 있음을 나타냅니다. 환경에서 직접 취한 리보솜 RNA (rRNA) 유전자의 이러한 조사는 재배 기반 방법 이 샘플에서 세균 및 고세균 종 의 1 % 미만을 발견했다 . [1] 메타 게 노믹스에 대한 많은 관심은 이전에 주목받지 못했던 미생물의 대다수를 보여준 이러한 발견에서 비롯된 것입니다.
이 분야의 초기 분자 연구 는 PCR 을 이용하여 리보솜 RNA 서열의 다양성을 탐구하는 Norman R. Pace 와 동료들에 의해 수행되었다 . [6] 이러한 획기적인 연구에서 얻은 통찰력으로 인해 Pace는 1985 년 초로 환경 시료에서 DNA를 직접 복제한다는 아이디어를 제안하게되었습니다. [7] 이로 인해 환경 시료에서 벌크 DNA를 분리 및 복제 하는 첫 번째 보고서가 발표되었습니다. Pace와 동료들은 1991 년에 [8] , Pace는 Indiana University 의 생물학과에 있었습니다. 이것들이 PCR이 아닌 것을 보장하는 상당한 노력가양 성의 복잡한 공동체의 존재를지지했습니다. 이 방법론은 고도로 보존 된 비 단백질 코딩 유전자 를 탐색하는 것으로 국한되었지만 다양성이 배양 방법에 의해 알려진 것보다 훨씬 더 복잡하다는 조기 미생물 형태학 관찰을 뒷받침했다. 그 후 얼마 지나지 않아 Healy는 1995 년 말린 풀밭 에서 실험실에서 자란 환경 생물체의 복잡한 배양 물로부터 만들어진 "zoolibraries"에서 기능 유전자의 메타 노미 얼적 고립을보고했다 . [9] Pace 실험실을 나온 Edward DeLong이 분야에서 계속되었으며, 해양 표본 으로부터 라이브러리를 구축 한 그의 그룹의 시작부터 서명 16S 서열에 기초한 환경 계통 발생에 대한 토대를 마련한 연구 결과를 발표했다 . [10]
2002 년에 Mya Breitbart, Forest Rohwer 및 동료들은 환경 산탄 총 시퀀싱 (아래 참조)을 사용하여 200 리터의 해수가 5000 가지 이상의 다른 바이러스를 포함하고 있음을 보여주었습니다. [11] 후속 연구에 따르면 인간 대변에는 바이러스 성 종이 1,000 개가 넘고 많은 박테리오파지를 포함 해 해양 침전물 1 킬로그램 당 수백만 개의 바이러스가있을 수 있습니다 . 본 연구에서 기본적으로 모든 바이러스는 새로운 종이었습니다. 2004 년에 Gene Tyson, Jill Banfield 및 캘리포니아 대학, 버클리 및 Joint Genome Institute 의 동료들은 산성 광산 배수 시스템 에서 추출한 DNA 염기 서열을 분석했습니다 . [12]이러한 노력으로 인해 이전에 이들을 배양하려는 시도에 저항했던 소수의 박테리아 및 고세균에 대한 완전하거나 거의 완전한 게놈이되었습니다 . [13]
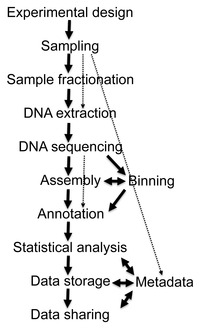
전형적인 metagenome 프로젝트의 흐름도 [14] 인간 게놈 프로젝트 의 개인 자금으로 조달 된 리더 인 Craig Venter 는 2003 년부터 전 세계를 주회하고 여행 중에 메타 게 노믹 샘플을 수집 하여 지구 해양 샘플링 원정 ( Global Ocean Sampling Expedition , GOS) 을 주도 했습니다. 이러한 모든 샘플은 새로운 게놈 (따라서 새로운 유기체)이 확인되기를 희망하는 샷건 시퀀싱을 사용하여 시퀀싱됩니다. Sargasso Sea 에서 진행된 시범 프로젝트 는 이전에는 볼 수 없었던 148 가지의 박테리아를 포함하여 거의 2000 종의 다른 종의 DNA를 발견했습니다 . [15] Venter는 지구를 일주 하고 미국의 서해안을 철저히 탐구했다.발트해 , 지중해 및 흑해를 탐험하기 위해 2 년간의 탐험을 마쳤습니다 . 이 여행 중에 수집 된 메타겐 데이터의 분석은 '잔치 또는 기근'의 환경 조건에 적응 된 분류군으로 구성된 두 그룹의 생물체와 주로보다 적게 풍부하지만 광범위하게 분포되어있는 플랑크톤 으로 구성된 분류군으로 구성된 두 그룹의 유기체를 밝혀 냈습니다 . [16]
2005 년 펜 스테이트 대학 (Penn State University)의 Stephan C. Schuster 와 동료들은 high-throughput sequencing으로 생성 된 환경 샘플의 첫 번째 서열을 발표 했습니다.이 경우에는 454 Life Sciences에서 개발 한 대규모 병렬 pyrosequencing 이 있었습니다. [17] 이 분야의 또 다른 초기 논문은 2006 년 샌디에고 주립 대학의 로버트 에드워즈 (Robert Edwards), 포레스트 로워 (Forest Rohwer )와 동료들에 의해 나타났습니다 . [18]
시퀀싱 [ 편집 ]
분자 생물학 기술의 최근 발전으로 인해 분자 복제를 위한 더 우수한 벡터 를 제공하는 박테리아 인공 염색체 (BAC) 에서 라이브러리 를 구축 할 수 있기 전까지는 환경 샘플 에서 수천 개의 염기쌍 보다 긴 DNA 염기를 회수하는 것이 매우 어려웠습니다 . [19]

환경 엽총 시퀀싱 (ESS). (A) 서식지에서 샘플링; (B) 입자를 전형적으로 크기로 여과하는 것; (C) 용해 및 DNA 추출; (D) 복제 및 도서관 건설; (E) 클론을 시퀀싱하는 단계; (F) 서열 조립을 콘티 그 및 비계로 도입 하였다. 산탄 총 metagenomics [ 편집 ]
생물 정보학의 진보 , DNA 증폭의 개선 및 계산 능력의 확산은 환경 샘플에서 추출한 DNA 서열 분석을 크게 지원하여 메타 건 샘플 (총 메타겐 샷건 또는 WMGS 시퀀싱이라고도 함) 에 샷건 시퀀싱 을 적용 할 수있었습니다 . 많은 배양 미생물과 인간 게놈 을 서열화하는 데 사용되는 방법은 DNA를 무작위로 절단하고 많은 짧은 서열을 서열화하고 이를 컨센서스 서열 로 재구성 한다. 산탄 총 시퀀싱은 환경 시료에 존재하는 유전자를 나타냅니다. 역사적으로이 시퀀싱을 용이하게하기 위해 복제 라이브러리가 사용되었습니다. 그러나 높은 처리량 시퀀싱 기술의 진보와 함께 복제 단계는 더 이상 필요하지 않으며 노동 집약적 인 병목 단계없이 시퀀싱 데이터의 더 많은 수율을 얻을 수 있습니다. 샷건 메타 게 노믹스는 어느 생물체가 존재하고 어떤 신진 대사 과정이 가능한지에 대한 정보를 제공합니다. [20]환경에서 유래 한 DNA의 수집은 대부분 통제되지 않기 때문에 환경 시료에서 가장 풍부한 생물이 결과 시퀀스 데이터에서 가장 잘 표현됩니다. 과소 대표 된 지역 사회 구성원의 게놈을 완전히 해결하는 데 필요한 높은 적용 범위를 달성하기 위해서는 대개 금지되어있는 큰 샘플이 필요합니다. 반면에 산탄 총 시퀀싱의 무작위적인 성격은 전통적으로 배양 기술을 사용하여 주목받지 못하는 많은 유기체가 최소한의 작은 서열 분절로 나타남을 보장합니다. [12]
높은 처리량 시퀀싱 [ 편집 ]
높은 처리량 시퀀싱을 사용 하여 수행 된 최초의 메타 게 노믹 연구는 대량 병렬 454 파이로 시퀀싱을 사용했습니다 . [17] 환경 샘플링에 일반적으로 적용되는 세 가지 다른 기술은 Ion Torrent Personal Genome Machine , Illumina MiSeq 또는 HiSeq 및 Applied Biosystems SOLiD 시스템입니다. [21] DNA 시퀀싱을위한 이러한 기술은 생거 시퀀싱 보다 짧은 단편을 생성 한다. 이온 토런트 PGM 시스템과 454 파이로 시퀀싱은 일반적으로 약 400bp의 읽기를 생성하고 Illumina MiSeq는 400-700bp의 읽기를 생성하며 (쌍 옵션의 사용 여부에 따라) SOLiD는 25-75bp의 읽기를 생성합니다. [22]역사적으로 이러한 판독 길이는 Sanger 시퀀싱 판독 길이가 ~ 750bp보다 훨씬 짧았지 만 Illumina 기술이이 벤치 마크에 빠르게 근접합니다. 그러나이 제한은 훨씬 더 많은 수의 시퀀스 읽기로 인해 보상됩니다. 2009 년 pyrosequenced metagenomes는 200-500 megabases를 생성하고 Illumina 플랫폼은 약 20-50 gigabases를 생성하지만이 산출량은 최근 몇 년 동안 증가했습니다. [23] 높은 처리량 시퀀싱의 또 다른 이점은 시퀀싱 전에 DNA를 복제 할 필요가 없으므로 환경 샘플링의 주된 편향 및 병목 현상 중 하나를 제거 할 수 있다는 것입니다.
생물 정보학 [ 편집 ]
메타 노 메믹스 실험에 의해 생성 된 데이터는 거대하고 본질적으로 시끄럽고 10,000 종을 대표하는 조각 데이터를 포함합니다. [24] 소의 반추위 metagenome 의 시퀀싱은 279 개의 기가 또는 279 억 개의 염기 서열 데이터 를 생성했다 . 반면 인간의 내장 microbiome 유전자 카탈로그는 567.7 개의 유전자를 567.7 개의 서열 데이터로부터 수집 한 것으로 밝혀졌다. [26] 이 크기의 데이터 세트에서 유용한 생물학적 정보를 수집, 큐 레이트 및 추출하는 것은 연구자에게 중요한 계산상의 어려움을 나타냅니다. [20] [27] [28] [29]
시퀀스 사전 필터링 [ 편집 ]
메타 게 노믹 데이터 분석의 첫 번째 단계는 여분의 낮은 품질의 서열 및 예상되는 진핵 생물 기원의 서열 (특히 인간 기원의 메타겐 성 물질) 의 제거를 포함한 특정 사전 여과 단계의 실행을 필요로합니다 . [30] [31] 진핵 게놈 DNA 서열을 오염의 제거에 사용할 수있는 방법은 Eu를 탐지를 포함하고 DeConseq. [32 ]
조합 [ 편집 ]
게놈과 메타 노미 믹 프로젝트의 DNA 서열 데이터는 본질적으로 동일하지만, 게놈 서열 데이터는보다 높은 커버리지 를 제공 하지만 메타 데이터 데이터는 대개 비 중복이다. [28] 또한, 읽기 길이가 짧은 2 세대 시퀀싱 기술의 사용이 늘어남에 따라 향후 메타 데이터 데이터의 대부분은 오류가 발생하기 쉽습니다. 이러한 요소들이 조합되면, 게놈으로의 메타 게놈 서열 판독을 어렵고 신뢰할 수 없게 만든다. Misassemblies는 샘플에 존재하는 종의 상대적 풍부 성의 차이로 인해 어셈블리를 특히 어렵게 만드는 반복적 인 DNA 서열 의 존재로 인해 발생합니다 . [34]Misassemblies는 하나 이상의 종의 서열을 키메라 컨 티그 (chimeric contigs) 로 조합 할 수있다 . [34]
어셈블리 의 정확성을 높이기 위해 페어 엔드 태그의 정보를 사용할 수있는 어셈블리 프로그램이 여러 개 있습니다 . Phrap 또는 Celera Assembler 와 같은 일부 프로그램 은 단일 게놈 을 어셈블하는 데 사용되도록 설계 되었지만 메타 데이터 데이터 세트를 어셈블 할 때 좋은 결과를 산출합니다. [24] 과 같은 다른 프로그램 벨벳 어셈블러 짧아에 최적화 된은 사용을 통해 제 2 세대의 순서에 의해 생성 된 판독 드 브루 인 그래프. 참조 게놈의 사용은 연구원들이 가장 풍부한 미생물 종의 집합체를 개선 할 수있게하지만이 접근법은 서열화 된 게놈을 이용할 수있는 작은 미생물 문에 의해 제한된다. [34] 어셈블리가 생성 된 후에 추가적인 도전은 "metagenomic deconvolution", 또는 어떤 시퀀스가 샘플의 어떤 종에서 왔는지 결정하는 것입니다. [35]
유전자 예측 [ 편집 ]
Metagenomic 분석 파이프 라인 은 조립 된 contig에서 코딩 영역의 주석에 두 가지 접근법을 사용합니다. [34] 첫 번째 방법은 이미 BLAST 검색을 통해 서열 데이터베이스 에서 공개적으로 이용 가능한 유전자와의 상 동성 을 기반으로 유전자를 확인하는 것이다 . 이러한 유형의 방법은 프로그램으로 구현되어 MEGAN 제 [36] 제, AB는 론적 관련 생물체에서 유전자 트레이닝 세트에 기초하여 영역을 코딩하는 예측 순서의 본질적인 기능을 이용한다. 이것은 GeneMark [37] 와 GLIMMER 와 같은 프로그램에 의해 취해진 접근법이다.. ab initio 예측 의 주요 이점은 시퀀스 데이터베이스에서 상 동체가없는 코딩 영역을 탐지 할 수 있다는 것입니다. 그러나 비교할 수있는 인접한 게놈 DNA의 넓은 영역이있을 때 가장 정확합니다. [24]
종 다양성 [ 편집 ]
유전자 주석은 "무엇"을 제공하는 반면, 종 다양성의 측정은 "누가"를 제공합니다. [39] metagenomes에서 커뮤니티 구성과 기능을 연결하려면 시퀀스를 binned해야합니다. Binning 은 특정 서열을 유기체와 연관시키는 과정입니다. [34] 유사성 기반 비닝에서와 같은 방법 BLAST는 급속 계통 마커 또는 기존의 공용 데이터베이스에 달리 유사한 시퀀스를 검색하기 위해 사용된다. 이 접근법은 MEGAN 에서 구현됩니다 . [40] 또 다른 도구 PhymmBL은 interpolated Markov 모델 을 사용 하여 읽기를 지정합니다. [24]MetaPhlAn 과 AMPHORA향상된 계산 성능으로 유기물의 상대적 존재 량을 추정하기위한 독특한 클레 드 특정 마커를 기반으로 한 방법입니다. [41] SLIMM 과 같은 최근의 방법 은 가짜 양성 반응을 최소화하고 신뢰할 수있는 상대적 존재 량을 얻기 위해 개별 참조 게놈의 판독 범위를 사용합니다. [42] 조성물 기반 비닝에서, 방법은 주파수 뉴클레오티드 또는 서열의 고유 기능을 사용하여 코돈 사용법 바이어스 . [24] 서열 비닝되면, 그 다양성과 풍부 비교 분석을 행할 수있다.
데이터 통합 [ 편집 ]
기하 급수적으로 늘어나는 시퀀스 데이터의 엄청난 양은 메타겐 프로젝트와 관련된 메타 데이터 의 복잡성으로 인해 복잡해지기는 어렵습니다 . 메타 데이터에는 샘플의 3 차원 (깊이 또는 높이 포함) 지리 및 환경 특성, 샘플 사이트에 대한 물리적 데이터 및 샘플링 방법론에 대한 자세한 정보가 포함됩니다. [28] 이 정보는 복제 가능성 을 보장 하고 다운 스트림 분석을 가능하게 하는 데 필요합니다 . 메타 데이터와 협업 데이터 검토 및 큐 레이션의 중요성으로 인해 GOLD (Genomes OnLine Database)와 같은 특수 데이터베이스에 표준화 된 데이터 형식이 필요합니다. [43]
메타 데이터와 서열 데이터를 통합하기 위해 몇 가지 도구가 개발되어 여러 생태 색인을 사용하여 다른 데이터 세트의 다운 스트림 비교 분석이 가능합니다. 2007 년 Folker Meyer와 Robert Edwards와 Argonne National Laboratory 및 Chicago 대학의 팀은 metagenome 데이터 세트 분석을위한 커뮤니티 리소스 인 Subsystem Technology 서버 ( MG-RAST )를 사용하여 Metagenomics Rapid Annotation을 발표했습니다 . [44] 14.8 terabases (14x10 위에로서 2012 년 6 월 12 DNA의 염기) 10,000 이상의 공용 데이터, 분석 하였다는 MG-RAST 내의 비교 자유롭게 설정 가능. 현재 8,000 명이 넘는 사용자가 MG-RAST에 총 50,000 개의 메타겐을 제출했습니다. 그만큼Integrated Microbial Genomes / Metagenomes (IMG / M) 시스템은 IMG ( Integrated Microbial Genomes ) 시스템과 Genomic Encyclopedia of Bacteria 에서 나온 참조 분리 게놈을 바탕으로 메타겐놈 서열에 기반한 미생물 군집의 기능 분석을위한 도구 모음을 제공합니다 및 Archaea (GEBA) 프로젝트. [45]
높은 처리량 metagonome 엽총 데이터를 분석하기위한 최초의 독립형 도구 중 하나는 MEGAN (MEta Genome Analyzer)입니다. [36] [40] 이 프로그램의 첫 번째 버전은 맘모스 뼈에서 얻은 DNA 서열의 메타겐 구조를 분석하기 위해 2005 년에 사용되었습니다. [17] 참조 데이터베이스에 대한 BLAST 비교를 기반으로이 도구는 간단한 LCA (lowest common ancestor) 알고리즘이나 SEED 의 노드를 사용하여 NCBI 분류의 노드에 읽기를 배치하여 분류 및 기능별 비닝을 수행합니다 또는 KEGG 분류. [46]
빠르고 저렴한 염기 서열 분석 장비의 출현으로 DNA 서열 데이터베이스의 성장은 이제 기하 급수적이다 (예 : NCBI GenBank 데이터베이스 [47] ). MG-RAST 나 MEGAN과 같은 BLAST 기반 접근법은 느리게 실행되어 큰 샘플에 주석을 달기 때문에 (예 : 중소 규모의 데이터 세트 / 샘플을 처리하는 데 몇 시간이 소요됨) 고효율 시퀀싱을 따라 가기 위해서는보다 빠르고 효율적인 도구가 필요합니다. [48] ). 따라서보다 저렴한 가격의 강력한 서버 덕분에 최근에는 초고속 분류기가 등장했습니다. 이러한 도구는 매우 빠른 속도로 분류 주석을 수행 할 수 있습니다 (예 : CLARK [49](CLARK의 저자에 따르면 "분당 3200 만 건의 짧은 읽기"를 정확하게 분류 할 수있다). 그러한 속도에서, 매우 큰 데이터 세트 / 십억 개의 짧은 읽기의 샘플이 약 30 분 내에 처리 될 수 있습니다.
대 DNA를 함유하는 샘플의 증가 가용성으로 인해 그 시료의 특성 (고 DNA 손상)와 연관된 불확실성, FALCON은 , [50] 보존 유사성 추정치들을 생성 할 수있는 고속 공구가 제공되고있다. FALCON의 저자에 따르면, 메모리와 속도 성능에 영향을주지 않고 편안한 임계 값을 사용하고 거리를 편집 할 수 있습니다.
비교 metagenomics [ 편집 ]
metagenomes 간의 비교 분석은 복잡한 미생물 군의 기능과 숙주 건강에서의 그들의 역할에 대한 추가적인 통찰력을 제공 할 수 있습니다. [51] metagenomes 인접 쌍 사이에 또는 다중 비교는 시퀀스 조성물의 수준에서 이루어질 수있다 (비교 GC 함량 , 분류 학적 다양성, 또는 기능적 보수 또는 게놈 크기). 인구 구조와 계통 발생 다양성의 비교는 16S와 다른 계통 발생 지표 유전자, 또는 낮은 다양성 집단의 경우 metagenomic dataset으로부터 게놈 재구성에 기초하여 이루어질 수있다. [52] metagenomes 간의 비교는 기능 등의 데이터베이스에 대해 참조 서열을 비교함으로써 이루어질 수있다 COG 나 KEGG카테고리별로 풍족을 표로 작성하고 통계적 유의성에 대한 차이점을 평가했다. [46] 이 유전자 중심 접근 방식의 기능적 보충 강조 사회 전체보다는 분류 학적 그룹으로, 그리고 기능적 보완 유사한 환경 조건 하에서 유사한 것을 보여준다. [52] 그 지역의 구조와 기능에 따라 환경의 영향을 연구 할 수있는 능력을 제공 연구자로 결과적으로, 샘플 군 유전체학의 환경 상황에 대한 메타 데이터를 비교 분석에서 특히 중요하다. [24]
또한 여러 연구에서 다양한 미생물 군집의 차이를 확인하기 위해 올리고 뉴클레오타이드 사용 패턴을 활용했습니다. 그러한 방법의 예로는 Willner et al.의 dinucleotide relative abundance 접근법이있다. [53] 그리고 Ghosh 등의 HabiSign 접근법. [54] 후자의 연구는 또한 tetranucleotide 사용 패턴에서의 차이는 유전자를 동정하는데 사용될 수있다 (또는 군 유전체학 읽기) 특정 서식처에서 발신을 나타내었다. 또한 TriageTools [55] 또는 Compareads [56] 와 같은 일부 메소드 는 두 개의 읽기 세트 사이에서 유사한 읽기를 감지합니다. 그들이 읽기에 적용 하는 유사성 측정 은 길이가 k 인 동일 단어 수를 기반으로합니다 읽기 쌍에 의해 공유됩니다.
비교 metagenomics의 주요 목표는 특정 환경에 특정 특성을 부여하는 책임이있는 미생물 그룹을 확인하는 것입니다. 그러나 시퀀싱 기술의 문제점으로 인해 metagenomeSeq와 같이 유물을 설명해야합니다. [27] 다른 사람들은 거주하는 미생물 군간의 미생물 상호 작용을 특성화했다. 커뮤니티 분석기 (Community-Analyzer)라고 하는 GUI 기반 비교 메타 게놈 분석 응용 프로그램은 Kuntal et al.에 의해 개발되었습니다. [57]이는 분석 된 미생물 군집 (분류 학적 구성의 측면에서)의 차이를 신속하게 시각화 할뿐만 아니라 내부에서 발생하는 고유의 미생물 상호 작용에 대한 통찰력을 제공하는 상관 관계 기반의 그래프 레이아웃 알고리즘을 구현합니다. 특히,이 레이아웃 알고리즘은 다양한 분류 학적 그룹의 존재 가치를 단순히 비교하는 것보다는 가능한 미생물 상호 작용 패턴에 기반한 메타겐의 그룹화를 가능하게한다. 또한이 도구는 사용자가 미생물에 대해 표준 비교 분석을 수행 할 수있게 해주는 몇 가지 대화식 GUI 기반 기능을 구현합니다.
데이터 분석 [ 편집 ]
생물 반응기 와 같은 천연 또는 공학적인 많은 세균 공동체에서 일부 유기체의 폐기물은 다른 물질의 대사 산물 인 신진 대사 ( Syntrophy ) 에 중요한 분업이있다 . [58] 한 예에있어서, 상기에서 메탄 생물 반응기 기능적 안정성이 몇몇의 존재가 필요 syntrophic 종 ( Syntrophobacterales 및 Synergistia 완전히 대사 폐기물 (원료에 자원을 설정하기 위해 함께 작동하는) 메탄 ). [59] 비교 연구와 microarrays 또는 proteomics 와 표현 실험을 사용하여연구자들은 종 경계를 넘어서는 신진 대사 네트워크를 구성 할 수 있습니다. 그러한 연구는 어떤 단백질의 버전이 어떤 종에 의해 그리고 어떤 종의 종에 의해 코딩되는지에 대한 상세한 지식을 필요로합니다. 따라서 지역 사회 게놈 정보는 대사 산물이 어떻게 지역 사회에 의해 이전되고 변형되는지를 결정하기위한 탐구에 또 다른 기본 도구 ( 대사 체학 과 프로테오믹스가있다)이다. [60]
Metatranscriptomics [ 편집 ]
Metagenomics는 연구원들이 미생물 군집의 기능적 다양성과 대사 적 다양성에 접근 할 수있게하지만, 이들 중 어느 것이 활동적인지를 보여줄 수는 없다. [52] 메타 노믹 mRNA ( metatranscriptome ) 의 추출과 분석 은 복잡한 공동체 의 조절 및 발현 프로파일에 관한 정보를 제공한다 . 환경 RNA의 수집에서 기술상의 어려움 ( 예를 들어, mRNA 의 짧은 반감기 ) 때문에 현재까지 미생물 군집에 대한 현장 전 사체 복제 연구는 상대적으로 거의 없었다 . [52] 원래 microarray에 제한되는 동안기술에서 metatranscriptomcs 연구는 전염 유전학 기술 을 사용 하여 미생물 군집의 전체 게놈 발현 및 정량을 측정했으며 [52] 처음에는 토양에서 암모니아 산화 분석에 사용되었습니다. [61]
바이러스 [ 편집 ]
Metagenomic sequencing은 특히 바이러스 성 연구에 유용합니다. 바이러스는 공통적 인 계통 발생 표식 ( 박테리아와 고세균의 경우 16S RNA , 유칼립카의 경우 18S RNA) 이 없으므로 환경 샘플에서 바이러스 성 지역 사회의 유전 적 다양성에 접근하는 유일한 방법은 메타겐 기능을 사용하는 것입니다. 바이러스 성 metagenomes (viromes라고도 함)는 바이러스 성 다양성과 진화에 대한 더 많은 정보를 제공해야한다 . [63] [64] [65] 예를 들어, Giant Virus Finder 라는 메타겐 파이프 라인 은 거대 바이러스 식염수 사막 [66] 과 남극 건조한 계곡에서. [67]
응용 프로그램 [ 편집 ]
Metagenomics는 다양한 분야에서 지식을 발전시킬 잠재력이 있습니다. 또한 의학 , 공학 , 농업 , 지속 가능성 및 생태계의 실제적인 문제를 해결하는 데에도 적용 할 수 있습니다 . [28]
전염병 진단 [ 편집 ]
감염성 및 비 전염성 질병을 구별하고 감염의 근본적인 병인을 확인하는 것은 상당히 어려울 수 있습니다. 예를 들어 최첨단 임상 실험실 방법을 사용한 광범위한 테스트에도 불구하고 뇌염 사례의 절반 이상이 아직 진단되지 않은 채로 남아 있습니다. Metagenomic sequencing은 환자 샘플에서 발견 된 유전 물질을 수천 개의 박테리아, 바이러스 및 기타 병원체의 데이터베이스와 비교함으로써 감염을 진단하는 민감하고 신속한 방법으로 기대됩니다.
창자 미생물 특성 [ 편집 ]
미생물 군락 은 인체 건강 을 유지하는 데 핵심적인 역할을 하지만, 이들의 구성과 메커니즘은 여전히 신비 스럽다. [68] 군 유전체학 서열은 적어도 250 개인에서 15-18 신체 부위에서 미생물 군집을 특성화하는 데 사용되고있다. 이것은의 일부인 인간 마이크로 바이 옴 이니셔티브 의 핵심이 있는지 확인하기 위해 주요 목표와 인간 마이크로 바이 옴 인간의 건강과 연관 될 수있는 인간 마이크로 바이 옴의 변화를 이해하고, 새로운 기술 및 개발, 생물 정보학 이러한 목표를 지원하기위한 도구. [69]
MetaHit (Metagomics of the Human Intestinal Tract) 프로젝트의 일환으로 진행된 또 다른 의학 연구는 덴마크와 스페인에서 온 124 명의 건강한 사람, 과체중 인 사람, 과민성 장 질환 환자들로 구성되었다. 이 연구는 위장관 박테리아의 깊이와 계통 발생 다양성을 범주화하려고 시도했다. Illumina GA 시퀀스 데이터와 SOAPdenovo를 사용하여 어셈블리 단기 판독을 위해 특별히 설계된 de Bruijn 그래프 기반 툴은 총 연결 길이 10.3 Gb 및 N50 길이 2.2 kb에 대해 500 bp보다 큰 658 백만개의 contig를 생성 할 수있었습니다.
이 연구는 두 가지 박테리아 분열물, Bacteroidetes 및 Firmicutes가 원위의 장내 세균을 지배하는 알려진 계통 발생 카테고리의 90 % 이상을 구성한다는 것을 입증했습니다. 소화관 내에서 발견 된 상대적 유전자 빈도를 이용하여이 연구자들은 장의 건강에 결정적으로 중요한 1,244 개의 메타 노미 클러스터를 확인했다. 이 범위 클러스터에는 두 가지 유형의 기능이 있습니다. 하우스 키핑과 내장에 특정한 기능입니다. 하우스 키핑 유전자 클러스터는 모든 박테리아에서 필요하며 주로 중앙 탄소 대사 및 아미노산 합성을 포함하는 주요 대사 경로에서 주요한 역할을합니다. 소화관 특유의 기능에는 숙주 단백질에 대한 접착력과 globoseries 당지질로부터의 당의 수확이 포함된다.
이 연구가 잠재적으로 가치있는 일부 의학적 응용을 강조하고 있지만 독서의 31-48.8 %만이 공공 인간 장내 세균 게놈 194 개와 GenBank에서 이용할 수있는 박테리아 게놈 7.6-21.2 %에 맞춰질 수있다. 소설 박테리아 게놈을 잡아 낸다. [70]
바이오 연료 [ 편집 ]
바이오 연료 있는 연료 유래의 바이오 매스 의 변환에서와 같이 변환, 셀룰로오스 에 함유 된 옥수수 , 줄기 지팽이 으로, 기타 미생물 셀룰로오스 에탄올 . [28] 이 과정은 셀룰로오스를 당 으로 전환시키는 미생물 학적 컨소시엄 (연결)에 의존하고 이어서 당의 에탄올 로 의 발효 에 달려있다 . 미생물은 또한 메탄 과 수소를 비롯한 다양한 바이오 에너지 원을 생산합니다 . [28]
바이오 매스 의 효율적인 산업 규모의 해체 는 높은 생산성과 저렴한 비용으로 새로운 효소 를 필요로합니다 . [25] 복잡한 미생물 군집 분석에 대한 메타 게놈 접근법 은 글리코 시드 가수 분해 효소 와 같은 바이오 연료 생산에서 산업적 응용과 함께 효소 의 표적 스크리닝 을 허용한다 . [71] 더욱이 이러한 미생물 군집이 어떻게 기능하는지에 대한 지식은 그것들을 조절할 필요가 있으며, 메타 게 노믹스 (metagenomics)는 그들의 이해에 중요한 도구이다. Metagenomic 접근법은 바이오 가스 발효기 와 같은 융합 미생물 시스템 [72]또는 곤충 초식 동물 등과 같은 곰팡이 정원 의 가위 개미 . [73]
환경 개선 [ 편집 ]
Metagenomics는 오염 물질 이 생태계 에 미치는 영향을 모니터링하고 오염 된 환경을 정화하는 전략을 개선 할 수 있습니다. 미생물 군이 오염 물질에 어떻게 대처하는지에 대한 이해가 높아짐에 따라 오염 된 곳에서의 오염 가능성을 평가하고 생물 증식 또는 생체 모방 실험이 성공할 확률이 높아집니다 . [74]
생명 공학 [ 편집 ]
미생물 군은 경쟁과 의사 소통에 사용되는 생물학적 활성 화학 물질의 광대 한 배열을 생산합니다. [75] 오늘날 사용되는 많은 약물은 원래 미생물에서 발견되었다; 최근에는 비 배양 가능한 미생물의 풍부한 유전 자원을 채취하여 새로운 유전자, 효소 및 천연물을 발견하게되었습니다. [52] [76] 메타 지노믹스의 애플리케이션의 개발을 허용 한 상품 및 정밀 화학 제품 , 농약 및 제약 의 이점 효소 - 촉매 의 키랄 합성이 점차 인식되고있다. [77]
메타 게 노믹 데이터 의 bioprospecting 에는 두 가지 유형의 분석이 사용됩니다. 즉 , 표현 형질에 대한 기능 중심 스크리닝 및 관심 대상 DNA 서열에 대한 서열 중심 스크리닝입니다. [78] 함수 기반 분석 생화학 적 특성 및 서열 분석 하였다 원하는 특성 또는 유용한 활성을 나타내는 클론을 식별하고자한다. 이 접근법은 적합한 스크린의 유용성 및 숙주 세포에서 원하는 형질을 발현 할 필요성에 의해 제한된다. 더욱이 발견 율이 낮고 (1,000 클론 당 스크리닝 당 하나 미만) 노동 집약적 인 성격 때문에이 접근법이 더욱 제한적입니다. [79] 한편, 서열 기반 분석을 사용하여 보존 된 DNA 서열을 하기 PCR 프라이머를 설계관심 서열의 클론을 스크리닝한다. [78] 서열 전용 더 접근하여 복제 기반 접근법과 비교에서, 벤치 필요한 작업량을 감소시킨다. 대용량 병렬 시퀀싱을 적용하면 생성되는 시퀀스 데이터의 양이 크게 증가하며, 이는 높은 처리량의 생물 정보 분석 파이프 라인을 필요로합니다. [79] 스크리닝에 서열 중심 접근법은 공개 서열 데이터베이스에 존재하는 유전자의 기능의 범위 및 정확도에 의해 제한된다. 실제로, 실험은 관심있는 기능, 선별 될 표본의 복잡성 및 기타 요인에 기초한 기능적 및 서열 기반 접근법의 조합을 사용합니다. [79 ]약물 발견을위한 바이오 테크놀로지로서의 메타 게 노믹스 (metagenomics)를 이용한 성공의 예가 말라시 딘 항생제로 설명된다. [81]
농업 [ 편집 ]
토양 식물이 자라는는 약 10 함유 토양 1 그램으로 미생물 군집 살고있다 9 -10 10 서열 정보의 약 gigabase를 포함 미생물 세포. [82] [83] 토양에 서식하는 미생물 군집은 과학에 알려진 가장 복잡한 것 중 일부이며 경제적 중요성에도 불구하고 제대로 이해되지 못하고있다. [84] 미생물 컨소시엄의 다양한 수행 생태계 대기압 질소 고정 포함한 식물 성장을 위해 필요한 영양분 순환 질병 억제 및 이산화탄소 격리 된 철 등의 금속 . [75]기능적 메타겐 방법 전략은 미생물 군집에 대한 재배 독립적 인 연구를 통해 식물과 미생물 간의 상호 작용을 탐색하는 데 사용되고있다. [85] [86] 영양 순환에 이전에 경작 또는 희귀 한 사회 구성원의 역할과 식물의 성장 촉진에 대한 통찰력을 허용함으로써, 군 유전체학 접근 방법이 개선 질환의 검출에 기여할 수있는 작물 과 가축 및 향상된의 적응 농업 개선 사례 미생물과 식물의 관계를 이용하여 작물의 건강을 유지하십시오. [28]
생태학 [ 편집 ]
Metagenomics는 환경 공동체의 기능적 생태계에 대한 귀중한 통찰력을 제공 할 수 있습니다. [87] 오스트레일리아 바다 사자의 배설물에서 발견 된 박테리아 컨소시엄에 대한 메타 게놈 분석은 영양이 풍부한 바다 사자 배설물이 연안 생태계의 중요한 영양 공급원이 될 수 있음을 시사한다. 이것은 배설물과 동시에 배출되는 박테리아가 배설물의 영양분을 먹이 사슬로 흡수 될 수있는 생체 이용 형태로 분해하기에 적합하기 때문입니다. 또한,
DNA sequencing은 물체에 존재하는 종을 확인하기 위해보다 광범위하게 사용할 수있다. [89] 공기로부터 여과 된 파편이나 먼지의 표본. 이것은 침입 종 과 멸종 위기 종 의 범위를 확립하고 계절 인구를 추적 할 수 있습니다.
참고 사항 [ 편집 ]









































































































